
Intel’s Xe2 has been confirmed and will first arrive in Lunar Lake CPUs, followed by the next-gen Arc discrete graphics lineup, codenamed “Battlemage”.
Intel Xe2 GPU Architecture Achieves a 50% Performance Improvement, Introduces New Ray Tracing Units and VVC Support, with Arc Battlemage Coming Soon!
At ITT 2024, Intel dismissed all rumors about the cancellation or delay of its GPU and Arc lineup. Tom Petersen delivered one of the most dynamic presentations at the event, which focused on the next-generation Xe2 architecture. Simplifying its approach, Intel is moving away from the LP, LPG, HP, and HPG labels, now branding its next-gen lineup simply as Xe2. Internally, these chips will still carry these codenames, but they will no longer be used client-side.
Intel set goals with Xe2 to achieve higher utilization, improved work distribution, and reduced software overhead. Starting from scratch, this architecture has addressed several major issues identified with Xe “Alchemist” GPUs. Intel impressed the audience initially with an IP performance efficiency chart showing gains of up to 12.5x, which are quite substantial. This deep dive will highlight what Xe2 is and how Intel is achieving these improvements.
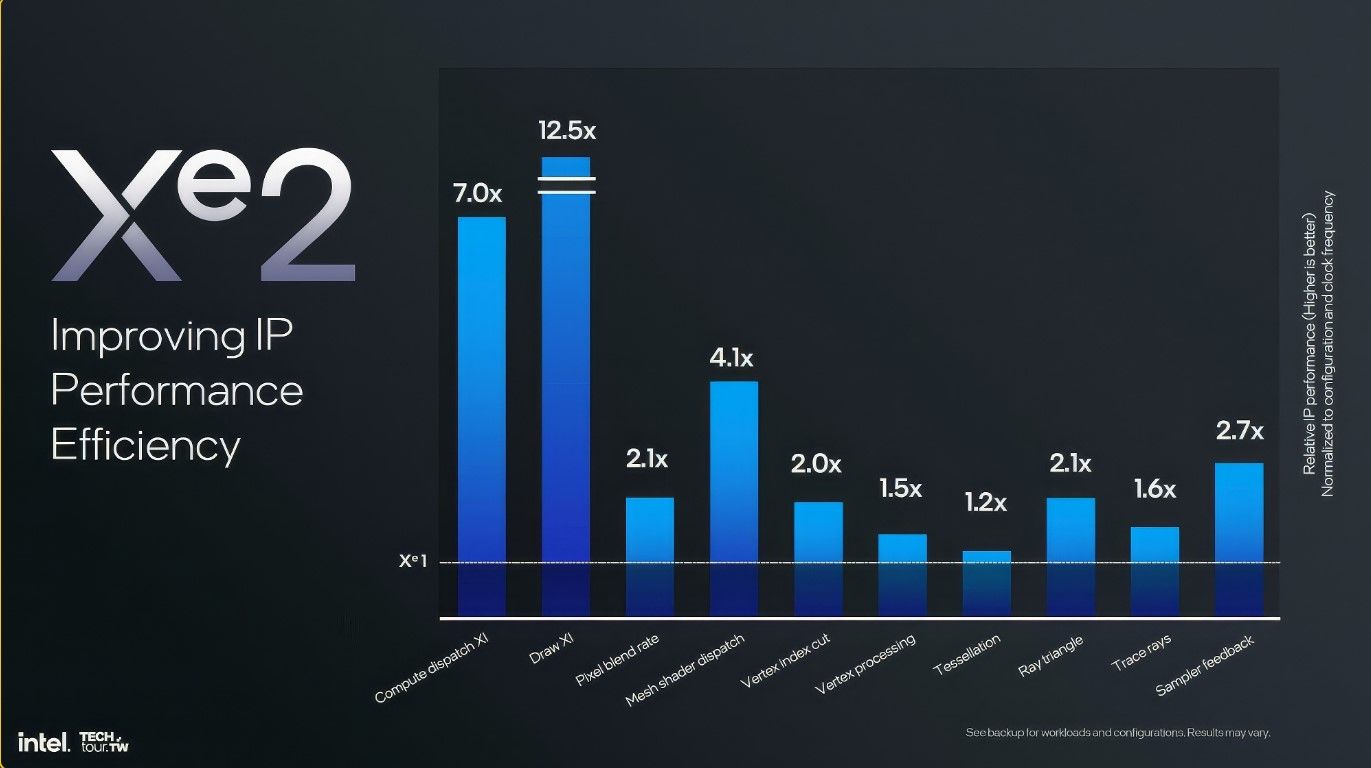
Intel asserts that the Xe2 architecture, like Xe, is highly scalable, which will enable its integration from low-power mobile SOCs such as Lunar Lake to high-end Arc graphics cards with discrete options that will be released later.
Intel Xe2 Architectural Deep Dive
Starting our deep dive, the second-generation Xe core, or Xe2, features repartitioned compute resources into native SIMD16 engines for increased efficiency.
The Xe2 core includes:
- 8 512-bit Vector Engines
- 8 2048-bit XMX Engines
- 64-bit atomic operations support
- 192KB Shared L1$/SLM
The Vector Engine has been updated to include:
- SIMD16 native ALUs – Support for SIMD16 and SIMD32 operations
- Xe Matrix Extensions (Support for INT2, INT4, INT8, FP16, BF16)
- Extended Math and FP64 – Transcendentals: SIN, COS, LOG, EXP
- 3-way co-issue – FP + INT/EM + XMX
The Xe Matrix Engines or XMX units were also present on Alchemist “Xe” GPUs, but now they support more data types and run much faster, with FP16 rated at 2048 OPS/clock and INT8 at 4096 OPS/clock.
Moving on, let’s examine how these new engines integrate into the Xe2 render slice, which are the foundational blocks of the Xe2 GPU. These Render Slices can be stacked and scaled as needed and are optimized to reduce latency, eliminate stalls, and improve hardware/software handshake. These Render Slices are connected to a Command Front End which natively supports Execute Indirect.
The render slice also includes a new Geometry engine with 3x vertex fetch throughput and 3x mesh shading performance (with vertex reuse), a new L1$/SLM cache for out-of-order sampling (with compressed textures), 2x throughput for unfiltered sampling and Programmable offsets, a new HiZ unit with 50% more cache and supports Early HiZ culling of small primitives. Finally, there are two new Pixel Backends that offer twice the blending throughput, a 33% increase in pixel color cache, and render target pre-fetch to L2$.
Xe2’s Latest Ray Tracing Unit Enhances Xe1
A key component of the Xe2 core is its RTU (Ray Tracing Unit), which features 3 traversal pipelines, 18 box intersections (6 per Box intersection and 3 boxes per RTU), and 2 triangle intersections.
Thus concludes the low-level overview of Intel’s Xe2 GPU architecture which offers:
- 2nd Gen Xe2 Cores
- Enhanced Vector Engines
- Deeper Caches
- New XMX Engines
- Performance and Efficiency – Optimized front-end
- Native hardware support for execute indirect commands
- Larger Ray Tracing Units
Overall, Intel’s Xe2 GPU architecture is designed to be more compatible with games and achieve higher utilization. The new Execute Indirect block is utilized by games to accelerate draw calls, and a 12.5x leap bodes well for gamers since it is heavily used by engines like Unreal Engine.
Intel Lunar Lake Receives the First Xe2 GPU IP, Full Deep Dive of Integrated Xe2
The first product to feature Xe2 GPUs is Lunar Lake, arriving in an integrated configuration. Several blocks within Lunar Lake are tied to the GPU, including the Media Engine and the Display Engine.
Let’s detail the Xe2 configuration for Lunar Lake:
- 8 Xe2 Cores
- 64 Vector Engines
- 2 Geometry Pipelines
- 8 Samplers
- 4 Pixel backends
- 8 ray tracing units
- 8 MB L2$
The Lunar Lake Xe2 GPU features 8 Xe2 cores, each with 8 XMX and 8 Vector units, a Load/Store unit, a Thread Sorting Unit, and a dedicated L1/L$ cache. Each of these four Xe2 cores forms a single Render Slice.

In terms of performance, compared to Meteor Lake’s Xe GPU, Intel states that the Xe2 GPUs achieved a 50% better performance at ISO and significantly lower power for the same performance.
The XMX block is also a notable component that sees the influx of 67 peak INT8 TOPS, contributing to the overall AI capability offered by the Lunar Lake CPUs. The chip as a whole offers 120 stage TOPs, including 48 TOPs from the NPU4 and 5 TOPs from the CPU itself.
Xe Display Engine for Lunar Lake
Now, shifting from the GPU to other blocks on the Lunar Lake CPU itself, starting with the Display Engine. The Display Engine comes with 3 Display Pipes with up to 8K60 HDR support, up to 3x 4K60 HDR support, and up to 1080p360 or 1440p360 support. The display engine supports HDMI 2.1, DisplayPort 2.1, and the new eDP 1.5 capabilities.
The front end of the Display Engine includes Decode/Decrypt and a Streaming Buffer Zone. For the pixel processing pipeline, you get 6 planes per pipeline with hardware support for color conversion and composition while being flexible and power-efficient.

Additionally, there’s a Low-Power optimized pipeline with Panel Replay (power gating during idle frames) and a new Brightness sensor with LACE (Local Adaptive Contrast Enhancement). On the compression and encoding side, you get a display stream compression engine with 31 visually lossless compressions and transport encoding (stream encode for HDMI and DisplayPort protocols). Router and Ports include Stream assembly and Port Routing with up to 4 ports supported for added flexibility.
Returning to eDP (eDisplayPort) 1.5 with Panel Replay, it’s being referred to as an evolution of panel self-refresh with selective updates with early transport and adaptive sync support. The new display capability offers reduced Judder and improved playback while offering higher power efficiency.
Xe Media Engine for Lunar Lake – VVC Support, Side-Cache, and Improved Encoding
The final block of the Lunar Lake SOC that is connected to the Xe2 GPU is the Media Engine, which now comes with its own dedicated 8 MB of shared side-cache. This new cache can be used by the rest of the chip, although there’s no need for it since the other cores have dedicated caches themselves.
This side-cache allows Lunar Lake a lot of bandwidth savings since there’s reduced traffic to system memory across media workloads. This also allows significant power reductions for encode tasks.
Delving into the Media Engine, it supports up to 8k60 10-bit HDR decode, up to 8k60 10-bit HDR encode, AVC, VP9, H.265 HEVC, AV1, and a brand-new VVC engine. The VVC engine significantly reduces bitrate while delivering the same quality as AV1 (up to 10% file size reduction). It also supports Adaptive Resolution Streaming and Screen content coding.

Lastly, we have the Windows GPU software stack which is ready for Xe2 GPUs. Intel stated that it spent a lot of time tuning the API-level performance of its Alchemist “Xe” GPUs, particularly DX9, but all that software work is now transitioning to Xe2 with support for all the latest APIs and Frameworks along with their runtimes.
That wraps up our extensive overview of Xe2, a brand-new graphics architecture that brings substantial performance improvements, the latest features, and much more to both integrated solutions like Lunar Lake and discrete options with the upcoming Arc Battlemage lineup. The company will share more details on Battlemage discrete offerings later in the year.






By Andrej Kovacevic
Updated on 14th July 2024